Thinking about Syncing, Part 2: timelines and change
In the first part of this series we established some definitions, concluding with a framing of synchronization as the merging of two timelines.
In this part we will examine some broad approaches to that problem.
The state of things
Some applications aren’t initially designed to sync. They’re designed to support a particular user experience, and their data storage reflects that experience. Sync support is added later.
When wiring syncing into an existing offline-first application, engineers tend to change as little as possible. (Indeed, Firefox Sync began as an optional add-on to Firefox, with no changes to Firefox’s internals at all.)
The application continues to store only the current local state — a snapshot, an instant along the timeline. Parts of this persistent state are now annotated with metadata — change counters, timestamps, global identifiers, tombstones — to allow changes to be tracked, extending the state to address the concerns of the sync code. Each time the state changes the old state is lost; only the metadata serves to indicate that a previous state existed.
The last synced state is kept on a server (often a simple object or document store) in much the same way. A simple latest-wins form of conflict resolution suffices to manage change, hoping that few conflicts will occur.
There are various permutations of this depending on how merges are performed and which actors in the system do the work, but the idea is the same. In this post we’ll call this snapshot-oriented sync.
Snapshot-oriented sync is simple and mostly non-intrusive, and for some applications it’s sufficient.
Merging
A client that fetches changes from the server and merges them with local state, without reference to earlier states, by definition performs a two-way merge (which isn’t really a merge at all!). If only one client writes at a time, this is all we need; the other timeline is known to be the previous state, and the change applies without conflict.
A more sophisticated client that tracks the earlier shared parent (prior to remote changes, local changes, or both) can perform a three-way merge, which is less likely to lose data when two clients make changes around the same time.
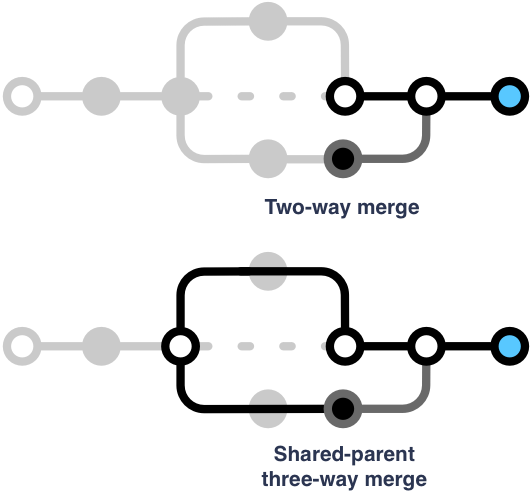
Note that in a snapshot-oriented approach — one that looks only at the current state of each client — the intermediate states aren’t available for use in the merge: some aren’t published to the server (and the rest aren’t preserved), so clients never see each other’s states, and the application doesn’t record its own fine-grained history.
At this point we don’t need to know how a merge works; it’s enough to know that a merge produces a unified timeline, and we can have more or less information available when we do so. A snapshot-based system might merge changed fields, or take one side over the other based on a timestamp, or even pause and ask the user to resolve a conflict.
The longer the duration between syncs, the more frequent the changes, the more coarse-grained the entities being synchronized, and the larger the volume of data, the more likely it is that the limitations of this approach will become apparent. It’s also difficult to avoid data loss without doing the necessary bookkeeping to support three-way merge, but that bookkeeping is onerous.
Tracking of change over time in a snapshot-oriented system can be done in a number of ways: e.g., if an application’s data model is relatively straightforward, clients might include in each object an explicit record of the client’s view of recent changes, using that record to do a better job of merging, or clients might keep a copy of the last snapshot seen during a merge.
In snapshot-oriented sync there is no first-class, explicit (certainly not explicit and long-lived) model of the passage of time, of change, or even of the state of other devices. As a result it’s hard to support features like restore, and it can be difficult to reason about the sync-related properties of the system.
Converging on change
Rather than copying state around, implicitly deriving and reconciling changes, we can instead copy changes around, and work with those. The goal is to reach the same state — to converge — on each client.
We can try to do this in several ways. We can send carefully designed events, as in Operational Transformation, relying on each client to transform and apply each operation in order to converge on the same state. We can restrict ourselves to a particular set of datatypes (CRDTs) that allow us to either send commutative updates or guaranteed-mergeable states between clients, such that by definition each client will reach the same state. Or we can track enough state that we can send deltas or diffs to each client, as in Differential Synchronization.
All change-oriented methods have advantages over an ad hoc state-based approach, but they make tradeoffs, have significant difficulties (particularly around ordered delivery of operations), and accrue some complexity: DiffSync must maintain shadow copies, OT must take great care with transformation to ensure that the system converges, and CRDTs limit storage design. OT and DiffSync have been widely used for collaborative editing tools, but these techniques are harder to apply to long-lived structured data across offline devices. There is very little discussion in the literature about the application of these specific techniques to client-encrypted data, where the server can’t help with diffing. (If you know of some, please let me know!)
We can call the application of these techniques to syncing transformation-oriented sync, because clients exchange the changes that should be applied to the other clients to achieve a desired outcome. (CvRDTs are technically an exception.) In transformation-oriented sync there is no long-lived model of change over time. The syncing protocol is nonetheless quite invasive and closely coupled to storage, because it relies on an accurate stream of changes as they occur, or tightly constrains the data structures used.
Events
If your application works solely in terms of commutative changes, with minimal or no deletion, and little need for managing identifiers, then simple replication of events — a trivial kind of CRDT — might be sufficient. For example, consider a music player that records an event each time a track is played, by name only. We can model this with a simple event object:
{"title": "Bohemian Rhapsody", "played": "2017–10–02T15:48:44Z"}
Clients can share these objects, and as soon as each client has the same set, they all have the same state.
Unfortunately, most applications are not this simple. How do we identify events in order to delete them? How do we represent richer track entries that might be renamed, linked to artists or albums, or be associated with cover art? How do we order events without comparing client clocks?
This approach is instructive, however, and we’ll return to it in Part 3.
Looking back to look forwards
In Firefox we see writes on different clients that conflict and need to be resolved with some finesse: one device bumps the lastUsed field of a login, another saves your new password in the password field, they race to sync, and — because desktop Firefox only does two-way merges — your password change is undone.
Firefox clients spend prolonged periods offline. Your work machine is offline all weekend, your cellphone is in Airplane Mode during the flight while you use your tablet on the overpriced Wi-Fi, and so on. Even when they are online, they can’t assume cheap, high-bandwidth connectivity.
Moreover, the set of Firefox Account clients isn’t definitively known in advance; a new device can sign in at any moment.
An application’s requirements might be even broader. Perhaps there’s a need for an audit trail or backup/restore functionality, or maybe it’s important that each client converge on exactly the same state. Convergence is a property that’s often expected but can’t be assumed, and indeed Firefox Sync clients do not necessarily converge, sometimes in surprising ways.
We know that snapshot-based syncing is limited: it forgets the sequence of events, making conflicts more difficult to resolve, and it has lots of other limitations. It seems natural to look for a mechanism that syncs changes, rather than snapshots. But transformation-oriented approaches, as used in Google Docs, are not a natural fit for long-lived, offline, encrypted systems.
With these requirements in mind there’s little alternative but to design around a history of change on each client and on the server, with one history being canonical. This ongoing record tracks enough of each timeline to allow for a three-way merge, with conflicts detected, and for offline and new clients to catch up incrementally without data loss. Clients themselves have the cleartext to merge.
Depending on other factors (e.g., whether clients need rapid random access to server storage), this design tends towards an implementation in which clients store and exchange deltas or revisions, collaboratively building a shared concrete timeline. DVCS tools are just like this: clients store sequences of commits, using merges and rebases to combine branches. In Git or Mercurial terms, the current agreed-upon state of the world is a particular branch, usually called master, and when a client pushes changes that branch is atomically advanced to a new ‘head’, a particular state that evolved from an earlier master.
We will call this log-oriented sync, because clients record a log of states — their own timeline — that diverges from a known shared history, and then refer to the logs of two timelines when merging. This is subtly different from transformation-oriented sync, because the log represents a sequence of recorded or merged states rather than an outgoing queue, and because the clients agree on history: there is a strict shared ordering of states. Local changes might need to be rebased or augmented when two timelines merge, but they definitely already happened.
CouchDB works like this: a revision tree stores history, automatically resolved conflicts refer to earlier revisions for manual repair, and synchronizing two CouchDB or PouchDB databases involves bidirectional replication of revisions.
Jay Kreps wrote an excellent and comprehensive treatise on the centrality of the log to modern data systems; it’s well worth the read.
Aside: the role of the server
Firefox Sync uses client-side crypto to achieve privacy guarantees, which by definition means that a central server can’t use the content of stored data to manage change control.
However, that only restricts the system’s ability to use a central server to resolve conflicts. For our purposes, let’s define a conflict as the presence on two timelines of two incompatible changes.
In a system with client-side crypto, conflicts typically need to be resolved by a client that can see cleartext.
It’s still possible to use a central coordinator to serialize writes and detect collisions, and of course to deliver changes to clients. It’s even possible to find data via salted and hashed metadata, allowing random or attribute-based access: Firefox Sync does this by giving each record a GUID and an optional sortindex field.
Conclusion
Bearing in mind that a sync is the process of reaching agreement between clients, we covered three basic approaches:
- Exchange snapshots of state, inferring changes when needed to resolve conflicts.
- Exchange streams of changes or diffs, applying them to each client’s state so that each client should converge on the same end state.
- Maintain a relatively long-lived history of changes, periodically merging each client’s timeline back with the main timeline.
This only partly answers the question of how to model application state; clearly there is interplay between how application data is represented and how it is synchronized, but that’s a long way from saying something concrete like “store state as JSON objects with vector clocks”. This is a big topic, so we’ll get to it in Part 3.