Thinking about Syncing, Part 1: timelines
I’ve been thinking about syncing data — in particular, about Firefox Sync, systems that touch it, and systems that might replace it — for about seven years now. I’ve been thinking about data representation in general for most of my career.
In that time I’ve begun to piece together a practical understanding of what we mean when we talk about syncing. This series of blog posts aims to capture some context and my mental model, and draw some conclusions that I think are true, given the constraints.
Comments, clarifications, and pointers to literature that I’ve missed would be very much appreciated.
In this blog post we will introduce the concept of a timeline, which is a linear sequence of states, and define syncing for our purposes as the process of merging two timelines.
Subsequent posts will cover some approaches to merging timelines, examine how the concerns of synchronization are in tension with other parts of an application, and suggest a model for resolving that tension by separating concerns.
Let’s start at the beginning: by exploring what sync systems do.
Facets of a sync system
“To sync”, at its most abstract, is to take two or more storage systems and make them agree on the state of their shared world.
There can be several reasons for doing this — to deliver a consistent user experience across devices, to safeguard the user’s data, to enable new product features — but the method is similar regardless.
Typically those systems will persist data, but in some cases it might be temporary. For example, Firefox Sync’s tab sync doesn’t write to disk. The current tabs are all fetched from the server when you launch Firefox, kept up to date during the session, then dropped when you quit.
Typically their interactions will be mediated by a central server, but they could also communicate directly.
Typically the state of the world is application data, usually data that reflects a user’s activity.
Typically clients (in my world they’re rich client applications like browsers) will sync more than once, keeping themselves “in sync” over time, but we can also imagine situations in which a client syncs only once.
Firefox Sync is typical in these senses. Your Firefox profiles periodically synchronize long-lived user data with each other, communicating via encrypted payloads stored on a central server that acts as a shared whiteboard.
The process of syncing is, at a slightly less abstract level, the process of exchanging enough facts that the clients can then converge on agreement.
Exchanging facts and reaching agreement can be as simple as a one-way overwrite of a file, or as complex as a fine-grained automatic merge over local Wi-Fi.
We can think about the commonalities of these processes in terms of timelines and merges.
Timelines and merges
Consider a particular state — your current to-do list, perhaps. That state is the successor of an earlier state, and the precursor of a later state. In the to-do list example the earliest state is an empty list. As you add items, delete them, and mark them as done, you change one state into another. We will call this ordered sequence of states a timeline. If you’re familiar with version control systems, you might think of this as a branch, though unlike VCSes most CRUD apps don’t keep the old states around.
The simplest networked systems don’t sync at all; there is a single timeline on a server, and only rendered state is held by the client. Traditional CGI web apps are this way: all persistent data is stored on a server, and changes are made by sending a request to that server. Your to-do list might look like this:
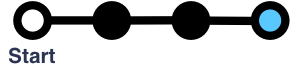
The next most simple are those that keep a copy of the state itself on each client, but only change it in one place. All attempted modifications are sent to the server to be applied to the canonical state. The server responds with updates to the client’s state; the server’s updates always win over any speculative changes made by the client. This is how Redux apps often work. This is syncing without any trouble: it’s a single loop of state transfer. There’s only one timeline, even if multiple clients are asking the server to make changes. All actions move inwards to the server, changes move outwards to the clients, and control over races is in the hands of the server.
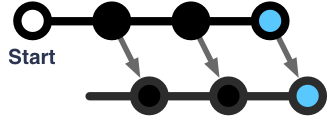
When we think of “syncing”, though, we usually think of systems in which multiple timelines can occur as part of normal operation. Those systems are more complex than an ordinary web app: they require the clients or the server to sometimes combine two timelines into one, or to maintain two timelines in parallel.
We can start to form a taxonomy of the more complex kinds of system by asking some questions. These questions are phrased in terms of a central server, but they generalize to peer-to-peer or local-only setups.
Can you record any permanent data before beginning to sync?
If so, multiple starting timelines need to merge at least once. This situation is unavoidable for a product with as long a history as Firefox — we have millions of users with precious bookmarks and logins on their devices, and they want to keep them when they start using a Firefox Account. If those users have more than one device, they’ll start with at least two separate timelines.

(Note that these little diagrams represent timelines — sequences of states — not the state of each device. After the merge there are still two clients, but they both agree on the same state of the world: they are at the same point on the same timeline.)
Can you record data while temporarily partitioned from the syncing infrastructure?
Clients might not be constantly communicating with the server or other clients. They might face network interruptions or outages, be running on a device that forbids background syncing or cellular data use, or the app might only sync on a schedule.
In these scenarios, clients must buffer outgoing changes, and the client or the server must perform little ‘mini merges’ on each sync. State changes on two devices temporarily result in two timelines, both of which must merge back.

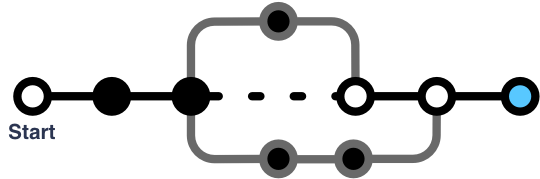
Can you stop using sync and keep your data?
If you stop syncing altogether — not just a temporary blip, but really signing out — can you record more data, then later resume use of sync? Or can you sign out of one account and sign in to another account with the same data?
This question implies some complex weaving of timelines; indeed, the production of new long-lived timelines. Each client can sign out, record some new data, restore from backups, and do all kinds of things before signing into the same or another account. Users really do these things (and worse!) and expect something sensible to happen. Some Firefox Sync users routinely sign in and out in order to tightly control when syncing happens, or to try to build unidirectional syncing workflows.

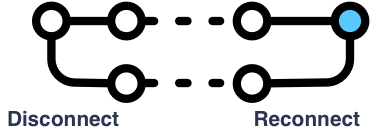
A user might even decide to take a device from one account to another.

Can a user rewrite history?
Can you restore from a local backup while sync is enabled? Can you permanently erase data?
Permanently erasing data — e.g., clearing your recent browsing history, or deleting saved logins — requires scrubbing the ‘official record’. Given that the official record is spread across multiple clients, and perhaps one or more servers, this can be complex. Even ordinary deletion isn’t necessarily trivial.
(Firefox Sync gets this wrong in some edge cases. The most obvious is history: visits, described by their timestamps and reasons, are stored as part of their parent history record, which holds the URL and current title, and that structure has no way to represent the deletion of an individual visit. Consequently, using the ‘Forget’ feature in Firefox to erase just part of your long-term interactions with a website has no effect on those visits that have already synced to another device.)
Conclusion
We began by defining syncing as the process by which clients converge on agreement about the state of their shared world.
We defined a timeline as an ordered sequence of states. We recognized that the simplest form of syncing is a one-way transfer of state corresponding to steps along a timeline. We came to a stipulative real-world definition of syncing as the transfer of such state that might require the merging of two timelines. We asked a number of questions, the answers to which determine when timelines might be created or merged.
Many apps say “no” to some or all of these questions. Firefox needs to support all of them; Firefox Sync clients have complex state, and periodically merge it with changes from other clients.
Saying “no” to some of these questions constrains the definition of syncing. Indeed, if you say “no” to all of the first three — mandatory account, no offline work, no disconnect — the app doesn’t meet our stipulative definition of syncing at all. Such an app is a website or a remoting system like X Windows or VNC, not a syncing system.
In future parts we will touch on the representation of states and timelines in an application, discuss some broad approaches to syncing, examine some of the tasks that must be performed in a syncing system, and finally discuss how support for sync should affect API design and how a client stores data.